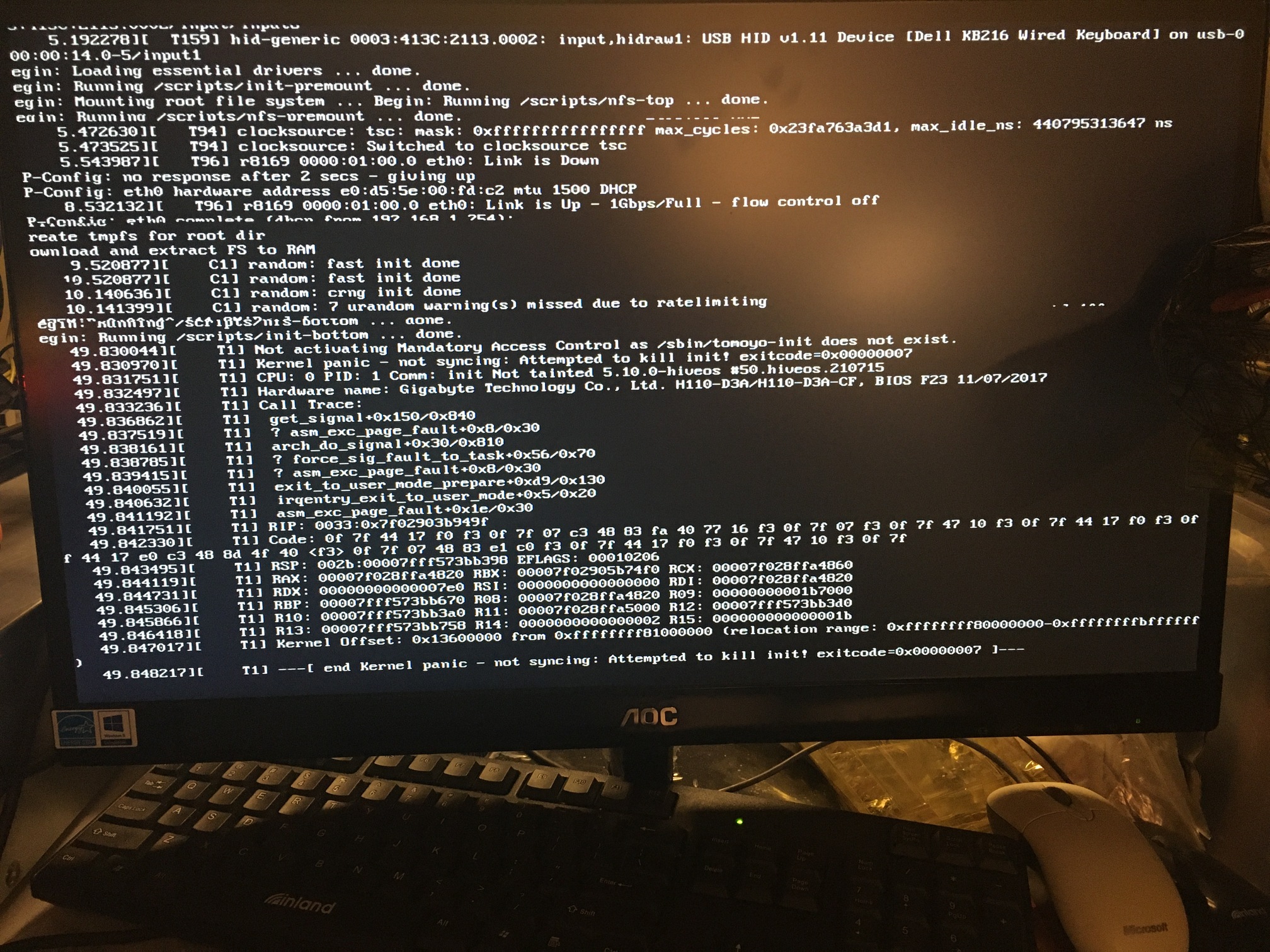
Let me see what I can do about that.
I’ll have to figure out all of the various places where information specific to my setup/configuration is stored and I’ll have to figure out how to strip all of that information out from it as well.
In addition to that, the current state of my backup file right now is about 7.3 GB in size (which will likely be a bit too large for people to be able to download in a reasonable and/or sensible fashion), so I’ll have to delete some of the backups from the backup_fs folder to make it smaller and more portable for people to download and use as a way to restore their PXE server as the current and temporary fix to this kernel panic issue, unless someone knows of a way to unpack it and maybe patch the kernel that they’re using or whatever might be the root cause/issue that’s causing said kernel panic.
Either way, let me see what I can do.
I’ll also have to figure out a way to publish the file (e.g. a site or location where I can publish a multi-GB 7-zip file). (If people have suggestions, I’ll gladly entertain them/take a look at those said suggestions.)
Thanks.
edit
Here is the link to the file, which I’ll host on my Google drive for about a week:
https://drive.google.com/file/d/1sZmf2hgC_vp_ohA4V2WMHQpDBxpKa7Kc/view?usp=sharing
SHA256:
e6032a7b43e8cccfc6c2aec76ee9c1d21d7ea3de2261d2a7097821ccebc8b8b8
Total file size:
1,439,864,662 bytes
I think that I stripped out all of my own personal, config-specifc information out from there, so it should be sanitized now.
You will need to download 7-zip/p7zip for your system/distro and I trust that you guys can figure out how to do that for your specific installation/distro/etc. (Google it.)
I would recommend that you download it and extract it on your Desktop (e.g. ~/Desktop) for your OS and then you can move the files to wherever they need to go for your specific installation.
You SHOULD be able to overwrite your existing files (which is causing the kernel panic anyways), but if you want to be safe, you can always backup your files (7-zip/p7zip is GREAT for that) before moving the files from my archive/backup and overwriting your own files.
Once you’ve confirmed that you are able to get your PXE server back up and running, then you can probably safely delete the bad copy of the PXE server files anyways.
Also, I will note for everybody here that after you download and extract the files, and you move them to where they need to go – you WILL need to run pxe-config.sh again to set up your farm hash, PXE server IP address, and anything else that you might need to setup/re-configure.
The server should be as recent as 2021-07-30, at which point, you can run sudo ./hive-upgrade.sh and when it asks you if you want to update the PXE server, select No and you should be able to proceed with upgrading the OS itself without upgrading the software that runs the PXE server itself.
I will also recommend that you check the dnsmasq.conf file because I also found that when I ran the hive-upgrade.sh multiple times, it will append the settings to your /etc/dnsmasq.conf multiple times. So, you might have to also go in there and make sure that’s cleaned up as well. (Not sure WHY it’s doing that, but it was just a behaviour that I observed that has popped up recently.)
Last but not least, also before you reboot your mining rigs, you’ll also want to make sure that atftpd, nginx, and dnsmasq servers/services are running properly by checking their status with sudo systemctl status and make sure that there aren’t any issues with any of those services otherwise, your mining rig may not work.
For example, because I had the issues where hive-upgrade.sh apparently seemed to keep appending to my /etc/dnsmasq.conf file, so when I rebooted my mining rig, it would say something like either it can’t pick up whatever dnsmasq is serving (my DHCP is managed by something else). Or another issue that I found was that if the atftpd service wasn’t running properly because there was a port 69 conflict with dnsmasq, (run sudo lsof -i -P -n | grep :69 to check for that), the mining rig wasn’t able to pick up the PXE boot file from the atftpd server (it will say something like PXE boot file not found or something along those lines).
So you’ll also want to check and make sure that’s up and running properly as well.
(You can also use sudo lsof -i -P -n | grep atftpd and ... | grep dnsmasq as well to see which ports those services are actually using. On my system, atftpd wasn’t listed (the service exited, but it doesn’t seem to be having an issue running, so [shrug] - I dunno - it appears to working. I’m not going to mess with it. My rig boots up and to me, that’s all that matters. dnsmasq appears to be using port 69.)
So yeah, check that to make sure that it is all up and running and in good, working order and then, go ahead and try and reboot/start your mining rig(s).
These are the issues that I’ve found when I was trying to run this most recent update (that it caused).
Your mileage may vary and you might encounter other problems that I haven’t written about here, so hopefully, things will work out for you and your specific installation/set up.
Again, I WILL say though, HiveOS’ diskless PXE boot IS really cool and nifty. There are still other issues with it, but for what it’s worth, I STILL do find it useful despite those other issues.