



Hey Miners, I have a 3 GPU set up a 3060, 3070 and a 3080. I can’t seem to get a Hashrate over 40MH/s. Both my 3060 and 3070 get 60 MH/s. Anyone have a clue as to whats going on?

Gigabutt 3080s, now aptly renamed Gigaburger 3080s, have become well known for their thermal throttling issues because the GDDR6 memory runs hot. Regardless of your OC settings, they throttle. I had to add thermal pads on the backplate in order for my 3080s to run normally. Ironically, they have the etched outlines of where to place the thermal pads on the inside of the back plate, which I didn’t notice until I did the last card. They just didn’t bother to do proper heat quality control because they were cheap. The thermal pads they do have on the memory ooze grease like a burger. No joke! I had to replace those too. There are plenty of posts around the web, but basically you need 2.5mm pad replacements for the inside of the card and the backplate. I used 2mm on the inside since I couldn’t find any quality 2.5mm in stock, which didn’t seem thick enough for proper contact, but worked out. I used 3mm thermals in between the backplate and the pcb. I found 3mm to be overly tight and pushing on the pcb, which makes me nervous because it is really sandwiched in there, but it worked out fine. Based on those findings, I’d recommend 2.5mm the whole way around if you can find them.
I was nervous opening up the first card, but it is not much different than assembling/disassembling motherboards components. I did have trouble with the single fan clip not coming out. There are 2 fan clips on 1 side of the board, and a single on the other. 4 out of 8 cards had trouble disconnecting the plastic fan clip from the pin housing. I had to torque it with a flat head screwdriver before it eventually came out, but not without chipping some plastic on the housing, but it had no affect on securing the clip during reassembly. I think they damn near glues the thing on. After 2 cards, at roughly 1.5 hours per card working at a slow pace, Q-tipping the oil off the memory and copper and cleaning with isopropyl, it was simply rinse and repeat with the remaining cards. My hash is steady at 98 and no thermal throttling. The card should do that out of the box but we are stuck investing extra time and money or live with a crap ROI and shortened card life span.I supplied some pics that should motivate you to do what Gigabutt failed to do and install quality thermal pads. I used Gelid extreme thermal pads: GELID Solutions | GP-Extreme Thermal Pad
Unfortunately, anything and everything that has to do with mining is overpriced due to supply and demand issue, as well as bot scalping assclowns.
Step 1: take out all the screws on the back plate. Should be 10.
Step 2: Gently pry off the backplate by holding both ends of the card. You’ll need to use a little pressure because the oil and GPU paste offer some resistance, but don’t rip it off because step 3 requires you to disconnect the fans.
Step 3: Once the housing is separated and you’re holding both sides an inch apart, disconnect the 2x fan clips first, which have come out very easily for me, then open the card up and lay it down on the table so you can access the single fan clip that is notoriously hard to remove. I literally ripped this thing off of the pcb pins on one of the cards because it was so tight, but was able to put it back on without issue.
Step 4. Remove the existing thermal pads on the copper (4 pieces) grab a q-tip or cotton swab and sop up the loads of grease on the memory. I recommend cleaning them with a conservative amount of isopropyl on the tip, then then another once over with a dry cue tip for any residual grease or iso.
Step 4, Install new thermal pads to replace what you took off on the copper, cutting them in roughly the same size and shape as what you took off. Goal is to cover the memory without getting to close to the GPU. You can just take a photo beforehand so you know where to place them or reference mine. It takes 2 packs of thermal pads to do 1 card. I used 1 pack of 2mm and 1 pack of 3mm.
Step 5. Take out the remaining 3 screws on the pcb to separate the pcb from the back plate.
Step 6. Add thermal pads. You can either go by my photos or look on the backplate for the etched outlines, as seen on the copper, of where to place the pads.
I’ll be making a video of the last card I do to help the community out since Gigabutt left us hanging. Red Panda’s video below helped, but didn’t really outline the pain in the ass step by step stuff. Check out the photos below and you’ll see I’m not joking about the grease emitted from their stock shit thermal pads.
Video “how to”: Adding Thermal PADS To My RTX 3080 For Higher Ethereum HASHRATE!? - YouTube
Gigaburger grease cleanup photos:






4 Likes
Wow Im impressed by the incredibly detailed reply. Yes I can confirm I have this same issue. But I have a peculiar situation. My 3080 was running super hot, I ran it in windows and saw that GDDR6X memory junction temp was 104 C. I booted hiveos back up and cut power to 195 W (I think around 60%). This dropped my core temp from around 61 C to 44 C. I cannot see the memory temp in Hiveos so I’m hoping that it followed in that drop. Weird thing is though, my hashrate is the exact same, around 84 - 86 Mh/s. Do you think this means that the memory is still roasting itself?
What are you settings?
Try -200, +1450, 60 TDP, and 90% fans
1450 may be too high, but check your temps and efficiency.
Im curious.
You are welcome. It has been a challenge to find a solution so happy to pay it forward. Absolutely the memory is getting grilled. It does not matter what you set the core, mem, or power to. I did the same thing and it runs fine for a few hours to a day then gets throttled. The memory will keep overheating due to the incredibly poor stock heat management. They did nothing, outside of crappy thermal pads on the front, to account for the mega memory heat so you are forced to invest into some thermal pads. There is nothing you can do, that I have tried or am aware of, to reduce the throttling from memory temps outside of installing and replacing thermal pads. This problem is specific to Gigaburger brand 3080s. My other 3080s have no thermal throttle issues due to memory heat at all. Sucks but at least there is a solution. I can confirm that I was hashing away at 97-98 with fans at 70-75 (minus the 2 I haven’t replaced thermal pads on) and power at 130w. If you have decent air flow, it is sustainable. I am using Nvidia driver 455.45.01 Take a look at my before and after temps/fan/hash below.
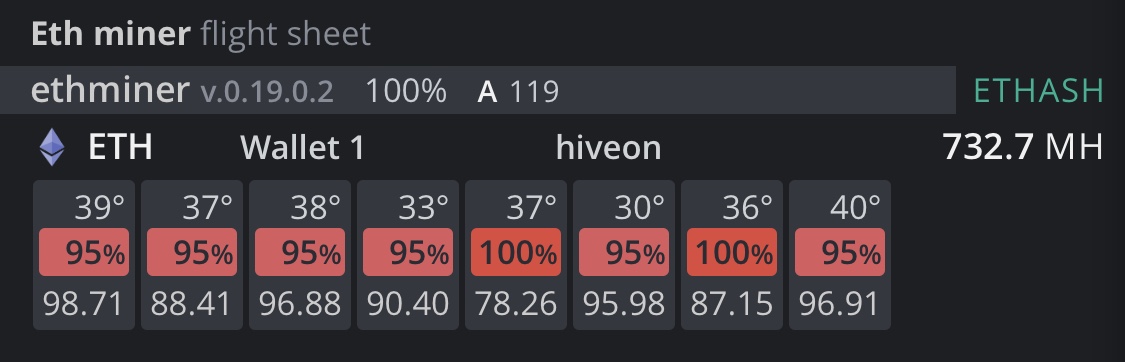
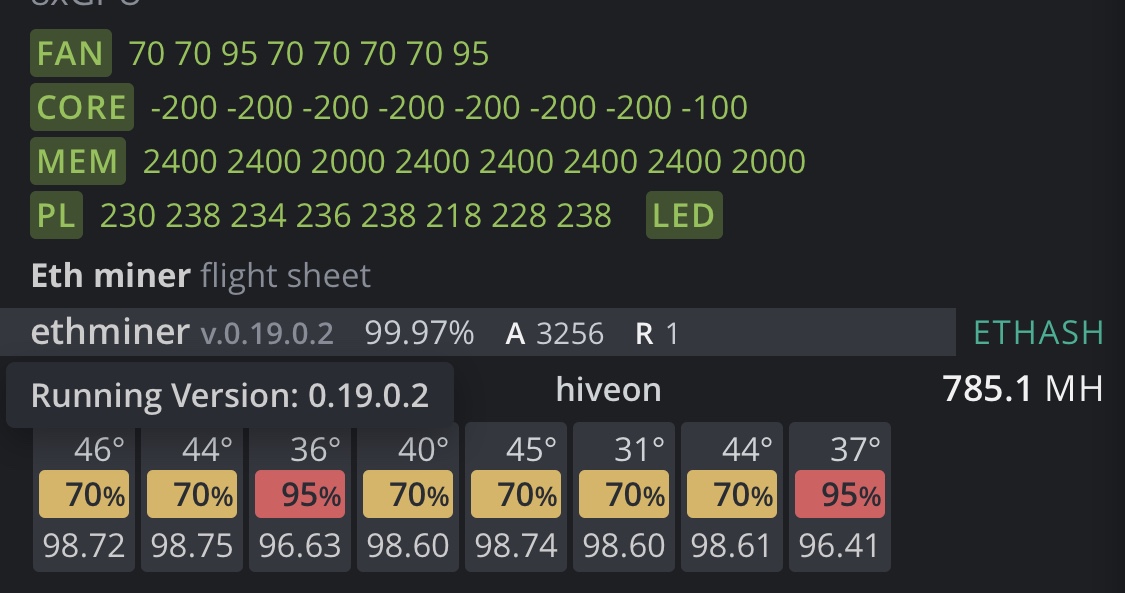
3 Likes
Ill try this, I gotta admit I am pretty new. When you say TDP, are you referencing the power limit? So 60 is 60%?
1 Like
Wow again thank you for imparting this knowledge, your info above was my solution after about a week of reading. No where on the internet have I seen this so well summarized.
I have a Geforce 3080 FE. Does this share the curse of the gigaburger? haha
Like I said above I am pretty new to messing around with this stuff. If I can get away with not opening up my graphics card, to me that would be ideal. Without aftermarket parts, I am actually pretty satisfied with my hashrate of around 86 Mh/s. Today I will run the miner in windows and watch stats in Hwinfo.
With really good airflow, running the fans at 80-90 and cutting power that produces a significant core temp drop, would you consider this sustainable for 24/7 mining? I realize its more or less impossible to say for sure without seeing stats over time, I am just nervous about reducing the longevity of the card.
1 Like
Read through this little guide I posted a while back. It explains a lot. Please focus on EFFICIENCY as I explain below.
And no you don’t have to worry. If you have a quality card mining won’t damage it. I have an EVGA 1080Ti FTW3 that has been mining for almost 4 years, almost continuously.
OC INFO
As soon as you apply a new OC the rig will respond.
There is a way to specify a delay and some miners feel that setting a long delay (I have seen 120 seconds) allows the DAG to be created before OC’ing and that this helps with error reduction.
The default is 5 seconds. I have mine set at 20 seconds.
The cards will kind of ramp up to those OC settings.
The cool thing is you can adjust OCs on the fly for individual cards and I do this based on errors. IF I apply an OC, I watch for errors and detune a card or cards based on that information. You can see in this screeshot I have some errors. I took some memory off these 2 cards and the errors stopped.
People will post and brag about OCs on these forums, so don’t get frustrated if your RIG won’t OC at the highest level. Make it run well and use less electricity. AND some days are better than others. Yesterday my cards were running better, right now, I will make some changes.

EFFICIENCY - a word about it.
ALL cards will clock differently - there are bad, good, great, and exceptional quality cards out there. It is the luck of the draw. Your OC values are heavily dependent on this and of course your entire system setup. Don’t chase other people’s OC settings. Work on yours and use error reporting within the HIVEOS dashboard to correct improperly OC’ed cards.
I have learned to focus on EFFICIENCY instead of HASHRATE.
Efficiency is the hash to watt ratio.
In other words how much work you get out of a card VS the power used by the card. This is the way to find the sweet spot for your card or rig(s).
Efficiency is calculated by taking a card’s hashrate/watts used. Since we need Joules for power, we need kilowatts so we multiply hashrate by 1000.
See below:
(62.27 Mh/s x 1000 watts/kW) / 120 watts = 520 kH/J as an example.
NOTE: (EFFICIENCY DATA - These values are available in the T-Rex miner data output)
This is one of my cards and that is a really good efficiency. I am sure someone is getting better efficiency on 3060Ti and so am I. I have one card that is approaching 520 kH/J - it is an exceptional card though. I feel 500 kH/J value is pretty average.
Check out this article on EFFICIENCY: NiceHash - Leading Cryptocurrency Platform for Mining and Trading
Even though this is from Nicehash ALL the information is solid.
The discussion on efficiency and how they tuned their rig for efficiency is really great - good pictures.
I have a 6 card rig of 1 x 3070 and 5 x 3060Tis pulling 830 watts at the wall (Killawatt measured) and hashing at around 370 Mh/s. There are 2 poorly performing cards in this rig.
I could probably run this entire rig from 1 x 1000 watt PSU. However, I am using 2 x 750 watt PSUs. The average per card efficiency is over 500 kH/J.
I have also found this helps me to identify UNDERPERFORMING cards which I can RMA back to EVGA for replacement.
LINUX - JUST A FEW COMMANDS
apt update - shows available Linux package updates
apt upgrade - applies ALL the updates available
nvidia-driver-update update the driver to 460.39 or whatever version you choose
nvidia-driver-update --nvs to reinstall the nvidia settings
BIOS - Ensure PCI-e on motherboard is in GEN2. You might or will get X Server Start errors and OC settings will not be applied.
Also check this out for BIOS settings - again this is NOT just for Nicehash. This is for all miners.
https://www.nicehash.com/support/mining-help/nicehash-os/nhos-recommended-bios-settings
2 Likes
Great info. Thanks!
More invaluable information, thank you.
Ah I thought you had a Gigabyte 3080. So you have the FE that has a single fan. Given ddr6 runs hot, you may want to consider thermal pads on the back plate to help. I honestly have not opened up a 3080 FE, but your problem sounds eerily similar to mine.
Right. I am, even considering water cooling as I’ve read that some people even with thermal pads continue to have issues.
The thing is, I’ve had no problems really. I’ve had this rig running for about a week and it was my own anxiety that led me to start worrying about the memory temperature. I’ve had an average hashrate that is almost exactly what I was expecting without overclocking or aftermarket mods. But, when I learned there were two GPU temperatures that needed to be monitored, and because HiveOS does not display the memory junction temp for the 3080/3090, I became worried. I exited HiveOS and booted up windows, ran lolminer and connected to my hiveon pool address. Ran Hwinfo and with total stock settings I saw a memory junction temp of 104C. So I exited the program, rebooted hiveOS and dropped the power level significantly which dropped core temp by a good bit. The hashrate has remained the same and is even a little higher now so that is giving me anxiety in that I suspect that I am still stressing out the GDDR6X. I am gonna go back into windows and do exactly what I’m doing now with the power level, fans etc and see what the memory temp does. I will report back.
Sounds good. Let me know your test results. I understand your paranoia. Last thing you want to do is grill the memory and kill the card. Especially in today’s priced out market.
Wow this is such a great response. Thanks so much! Hopefully this will solve it. I really appreciate the answer. Happy mining!
So I spent the better part of yesterday mining from windows with T-Rex miner as well as with MSI afterburner and Hwinfo running as well. I tested all sorts of combinations in settings while watching the memory junction temp that is not currently displayed while running hiveos. What I saw was interesting:
At 100% power, stock settings GDDR6X was as hot as 106 C with a hashrate of about 84 Mh/s.
At 70% power, fans at 80%, otherwise stock settings GDDR6X was sitting at 98 C. Hashrate of 86 Mh/s
At 60% power, fans at 80%, otherwise stock settings GDDR6X was sitting at 96 C. Hashrate of 86-88 Mh/s.
At 60% power, -200 core, +600 mem, fans 80%, GDDR6X was back at 98 C with a hashrate of 92 Mh/s.
At 60% power, -200 core, -200 mem, fans 80%, I finally saw what felt like an appreciable temp drop to 92 C, that bounced between 92 and 94, and sat kinda steadily at 94 C with a hashrate of 85 mh/s.
The only way I saw a real temp drop, that kept the VRAM in the 80s range was if I cut power to 55% and let the hashrate fall to 65 - 70 Mh/s.
So what I decided to go with for now is power level of 192 W (60%), -200 core, -200 mem, and a GDDR6X temp of 94 C. To me this felt like a solid compromise. Only slight hashrate drop, and a stable mid 90s temp. I’m still gambling on the fact that this temp is sustainable, because I don’t think there is a good consensus on the heat tolerance these new chips. 100s range seems absurd, but I would hope that this is just a characteristic of a new more powerful generation of VRAM chips. What do yall think? Is 94 C still too hot?
Just for everyone’s info, this is on a Nvidia 3080 FE with no aftermarket cooling.
I did try these, unfortunately as soon as I set the 1450 overclock, my screen went black and I had to restart the computer. Everything seems to be running fine so I’m not entirely sure what did this.
In terms of the efficiency, I need to spend a little more time tuning but for the time I had yesterday, the settings of 196 W, -200 core, -200 mem, 80% fans, seemed to be the most efficient. Although I wasn’t being terribly scientific about it and should have been better about logging the actual numbers.

Try to core -250, mem 2400, PL 240
I’ve found that 2400 mem (on some cards) seems to be the threshold before the card starts erring out or invalid/stale shares start popping up. In windows this translates to 1200, by the way. In HiveOS you have to double the memory number to 2400 to match a 1200 setting using Windows. It is certainly a task on a card-by-card basis, even if they are the same brand. I get wildly different results even in the same brand line and I’ve found it takes some time to see how things run and tweak.
1 Like